Канал Nuances of programming опубликовал перевод статьи Jekaterina Kokatjuhha: «Web Scraping Tutorial with Python: Tips and Tricks»

Как-то я хотела купить авиабилеты и заметила, что цены изменяются несколько в течение дня. Я попыталась выяснить, когда наступает самый лучший момент для покупки билетов, но не нашла в Интернете ничего, что бы могло мне помочь решить эту задачу. Тогда я написала небольшую программу для автоматического сбора данных в Интернете – так называемую программу скрепинга. Программа извлекла информацию по моему запросу для определенного пункта назначения на выбранные мной даты и показала мне, когда стоимость становится минимальной.
Я имею большой опыт веб-скрепинга и хочу с вами поделиться.
Этот пост предназначен для тех, кому интересно узнать об общих шаблонах проектирования, подвохах и правилах, связанных с веб-скрепингом. В статье представлено несколько реальных примеров и перечень типовых задач, таких как, например, что делать, чтобы вас не обнаружили, что можно делать, а что не следует и, наконец, как ускорить работу вашего скрепера с помощью распараллеливания.
Все примеры будут сопровождаться фрагментами кода на Python, так что вы можете сразу же ими воспользоваться. В этом материале также будет показано, как привлекать к работе полезные пакеты Python.
Реальные примеры
Существует различные причины и варианты необходимости использования сбора (скрэпинга) данных в Интернете. Позвольте мне перечислить некоторые из них:
- сбор данных со страницы электронного магазина, чтобы определить имеется ли в наличии одежда, которую вы хотите купить, со скидкой
- сравнить цены нескольких брендов одежды, собирая данные о них с вэб-страниц
- стоимость авиабилетов может меняться несколько раз в течение дня. Можно сканировать веб-сайт и дождаться момента, когда цена будет снижена
- проанализировать веб-сайты, чтобы определить, должна ли быть стартовая стоимость продажи низкой или высокой, чтобы привлечь больше участников на аукцион или коррелирует ли длительность проведения аукциона с более высокой ценой конечной ценой продажи
Руководство
Структура руководства:
- Применяемые пакеты
- Основной программный код
- Распространенные ошибки
- Общие правила
- Ускорение ‑ распараллеливание
Прежде чем мы приступим: БУДЬТЕ аккуратны с серверами; вы же НЕ ХОТИТЕ сломать вэб-сайт.
1. Известные пакеты и инструменты
Для веб-скрэпинга нет универсального решения, поскольку способ, с помощью которого хранится на каждом из веб-сайтов обычно специфичны. На самом деле, если вы хотите собрать данные с сайта, вам необходимо понять структуру сайта и, либо создать собственное решение, либо воспользоваться гибким и перенастраиваемым вариантом уже готового решения.
Изобретать колесо здесь не нужно: существует множество пакетов, которые скорее всего, вам вполне подойдут. В зависимости от ваших навыков программирования и предполагаемого варианта использования вы можете найти разные более или менее полезные для себя пакеты.
1.1 Проверяем параметры
Чтобы вам было проще проверять HTML-сайт, воспользуйтесь опцией инспектора в вашем вэб-браузере.
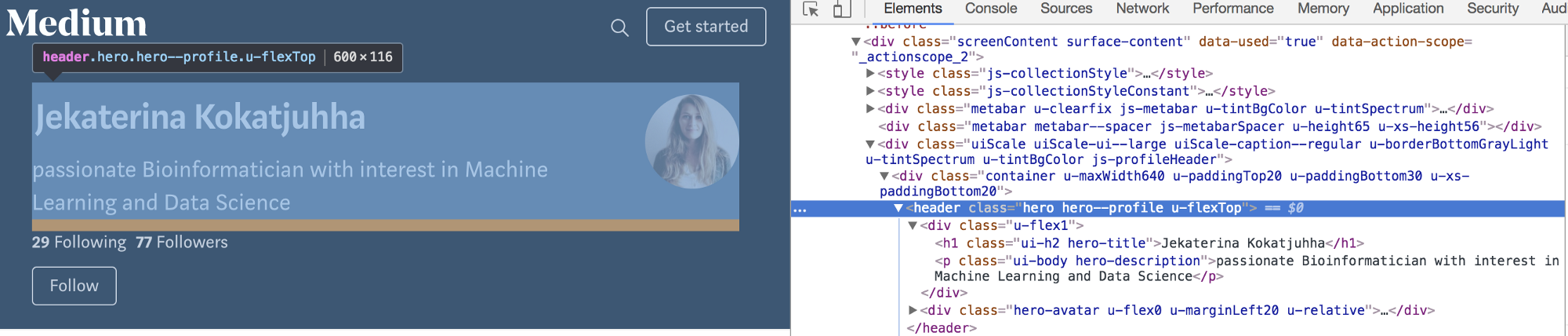
Раздел веб-сайта, который содержит мое имя, мой аватар и мое описание, называется hero hero--profile u-flexTOP (любопытно, что Medium называет своих писателей героями:)). Класс <h1>, который содержит мое имя, называется ui-h2 hero-title, а описание содержится в описании героя <p> классом ui-body hero-description.
Вы можете более подробно познакомиться с HTML-тэгами и различиями между классами и id здесь.
1.2 Скрэпинг
Существует отдельная готовая к использованию библиотека для извлечения данных под названием Scrapy. Кроме извлечения HTML, этот пакет располагает большим количеством функций, таких как экспорт данных в различные форматы, создание лог-файлов и т.д. Это достаточно гибкий и настраиваемый вариант: запуск отдельных скрэперов на разных процессах , отключение cookies (некоторые сайты используют cookies для идентификации ботов) и установка задержек загрузки (веб-сайт может быть перегружен из-за огромного количества запросов на сканирование). Его также можно использовать для извлечения данных с помощью API. Однако для начинающих программистов пакет, скорее всего, будет несколько сложноват: вам придется прочитать руководства и разобраться с примерами, прежде чем вы сможете приступить к работе.
В моем случае я воспользовалась готовым методом «из коробки»: я просто хотела извлечь ссылки со всех страниц, получить доступ по каждой ссылке и извлечь из нее информацию.
1.3 BeautifulSoup с библиотекой Request
BeautifulSoup – это библиотека, позволяющая сделать синтаксический разбор (парсинг) HTML-кода. Кроме того, вам также потребуется библиотека Request , которая будет отображать содержимое URL-адреса. Однако, вы также должны позаботиться и о решении ряда прочих вопросов, таких как обработка ошибок, экспорт данных, распараллеливание и т.д.
Я выбрала BeautifulSoup, поскольку эта библиотека помогла мне понять сколько всего Scrapy может делать самостоятельно и, я надеюсь, помогла мне быстрее научиться на своих собственных ошибках.
2. Основной программный код
Начать скэпить вэб-сайт очень просто. В большинстве случаев просматриваете HTML-сайт, вы обнаружите те классы и идентификаторы, которые могут вам могут понадобиться. Допустим, у нас есть следующая структура html, и мы хотим извлечь элементы main_price.
Примечание: элемент discounted_price является необязательным.
[html]<body>
<div id="listings_prices">
<div class="item">
<li class="item_name">Watch</li>
<div class="main_price">Price: $66.68</div>
<div class="discounted_price">Discounted price: $46.68</div>
</div>
<div class="item">
<li class="item_name">Watch2</li>
<div class="main_price">Price: $56.68</div>
</div>
</div>
</body>[/html]
Основной код вэб-скрепера должен импортировать библиотеки, выполнить запрос, проанализировать html и затем найти класс class main_price.
[python]
from bs4 import BeautifulSoup
import requests
page_link =’https://www.website_to_crawl.com’
# fetch the content from url
page_response = requests.get(page_link, timeout=5)
# parse html
page_content = BeautifulSoup(page_response.content, "html.parser")
# extract all html elements where price is stored
prices = page_content.find_all(class_=’main_price’)
# prices has a form:
#[<div class="main_price">Price: $66.68</div>,
# <div class="main_price">Price: $56.68</div>]
# you can also access the main_price class by specifying the tag of the class
prices = page_content.find_all(‘div’, attrs={‘class’:’main_price’})[/python]
Может случиться так, что класс main_price находится в другом разделе веб-сайта. Чтобы избежать извлечения ненужного класса main_price из какой-либо другой части веб-страницы, мы могли бы сначала обратиться к id listings_prices и только затем найти все элементы с классом main_price.
3. Распространенные ошибки
3.1 Check robots.txt
Правила скрэпинга веб-сайтов можно найти в файле robots.txt. Вы можете найти его, написав слова «robots.txt» после имени домена, например так: www.website_to_scrape.com/robots.txt. Эти правила определяют, какие части веб-сайтов не могут быть автоматически извлечены или как часто боту разрешено запрашивать данные со страницы. Большинство не заботятся об этих правилах, но все же постарайтесь хотя бы почитать их, даже если вы и не планируете следовать им.
3.2 HTML может быть злом
HTML-теги могут содержать идентификатор (id), класс или сразу оба этих элемента. Идентификатор (т.е. id) HTML описывает уникальный идентификатор, а класс HTML не является уникальным. Изменения в имени или элементе класса могут либо сломать ваш код, либо выдать вам неправильные результаты.
Есть два способа избежать, или, по крайней мере, предупредить это:
• Используйте конкретный идентификатор id, а не class, поскольку он с меньшей вероятностью будет изменен
• Проверьте, не возвращается ли элемент значение None.
[python]price = page_content.find(id=’listings_prices’)
# check if the element with such id exists or not
if price is None:
# NOTIFY! LOG IT, COUNT IT
else:
# do something[/python]
Однако, поскольку некоторые поля могут быть необязательными (например, discounted_price в нашем HTML-примере), соответствующие элементы не будут отображаться в каждом списке. В этом случае вы можете подсчитать процентное соотношение частоты возврата None конкретным элементом в списке. Если это 100%, вы, возможно, захотите проверить, было ли изменено имя элемента.
3.3 Обмануть программу-агент
Каждый раз, когда вы посещаете веб-сайт, он получает информацию о вашем браузере через пользовательский агент. Некоторые веб-сайты не будут показывать вам какой-либо контент, если вы не предоставите им пользовательский агент. Кроме того, некоторые сайты предлагают разные материалы для разных браузеров. Веб-сайты не хотят блокировать разрешенных пользователей, но вы будете выглядеть подозрительно, если вы отправите 200 одинаковых запросов в секунду с помощью одного и того же пользовательского агента. Выход из этой ситуации может заключаться в том, чтобы сгенерировать (почти) случайного пользовательского агента или задать его самостоятельно.
[python]# library to generate user agent
from user_agent import generate_user_agent
# generate a user agent
headers = {‘User-Agent’: generate_user_agent(device_type="desktop", os=(‘mac’, ‘linux’))}
#headers = {‘User-Agent’: ‘Mozilla/5.0 (X11; Linux i686 on x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.63 Safari/537.36’}
page_response = requests.get(page_link, timeout=5, headers=headers)[/python]
3.4 Время ожидания запроса
По умолчанию Request будет продолжать ожидать ответ в течение неопределенного срока. Поэтому рекомендуется установить параметр таймаута.
[python]# timeout is set to 5 secodns
page_response = requests.get(page_link, timeout=5, headers=headers)[/python]
3.5 Я заблокирован?
Частое появление кодов состояния, таких как 404 (не найдено), 403 (Запрещено), 408 (Тайм-аут запроса), может указывать на то, что вы заблокированы. Вы можете проверить эти коды ошибок и действовать соответственно.
Кроме того, будьте готовы обработать исключения из запроса.
[python]try:
page_response = requests.get(page_link, timeout=5)
if page_response.status_code == 200:
# extract
else:
print(page_response.status_code)
# notify, try again
except requests.Timeout as e:
print("It is time to timeout")
print(str(e))
except # other exception[/python]
3.6 Смена IP
Даже если вы рандомизировали своего пользовательского агента, все ваши запросы будут отправлены с одного и того же IP-адреса. Это вполне нормально, поскольку библиотеки, университеты, а также компании имеют всего несколько IP-адресов. Однако, если очень много запросов поступает с одного IP-адреса, сервер может это обнаружить.
Использование общих прокси, VPN или TOR может помочь вам стать незаметным;)
[python]proxies = {‘http’ : ‘http://10.10.0.0:0000’,
‘https’: ‘http://120.10.0.0:0000’}
page_response = requests.get(page_link, proxies=proxies, timeout=5) [/python]
Если вы используете общий прокси-сервер, веб-сайт увидит IP-адрес прокси-сервера, а не ваш. VPN соединяет вас с другой сетью, а IP-адрес поставщика VPN будет отправлен на веб-сайт.
3.7 Ловушки для хакеров
Ловушки для хакеров – это средства для обнаружения сканеров или скреперов.
Такими средствами могут быть «скрытые» ссылки, которые не видны пользователям, но могут быть извлечены скреперами и/или вэб-спайдерами. Такие ссылки будут иметь набор стилей CSSdisplay:none, их можно смешивать, задачая цвет фона или даже перемещаясь из видимой области страницы. Как только ваша программа посещает такую ссылку, ваш IP-адрес может быть помечен для дальнейшего расследования или даже мгновенно заблокирован.
Другой способ обнаружить хакеров – это добавить ссылки с бесконечно глубокими деревьями директорий. В этом случае вам нужно ограничить количество загруженных страниц или ограничить глубину обхода.
4. Общие правила
- Перед началом скрэпинга проверьте, есть ли у вас возможность воспользоваться публичными API. Публичные API предоставляют более простой и быстрый (и законный) поиск данных, по сравнению с веб-скрэпингом. Посмотрите API Twitter, который предоставляет API для различных целей.
- Если вы скрэпите много данных, вы можете воспользоваться базой данных, чтобы иметь возможность быстро анализировать получать данные с Интернета. В этом руководстве описано, как создать локальную базу данных с помощью Python.
- Будьте вежливы, терпеливы и уважительны. Как следует из этого ответа, рекомендуется оповещать пользователей о том, что вы собираете данные с их веб-сайта, чтобы они могли лучше отреагировать на возможные проблемы, причиной которых может стать ваш бот.
Опять таки, не перегружайте веб-сайт, отправляя сотни запросов в секунду.
5. Ускорение ‑ распараллеливание
Если вы решитесь на распараллеливание своей программы, будьте осторожны с реализацией, чтобы не «свалить» сервер. Обязательно прочитайте раздел «Распространенные ошибки», приведенный выше. Ознакомьтесь с определениями параллельного и последовательного выполнения, процессоров и потоков здесь и здесь.
Если вы извлекаете большое количество информации со страницы и выполняете некоторую предварительную обработку данных, количество повторных запросов в секунду, которое вы отправляете на страницу, может быть относительно низким.
В своем другом проекте я собирала цены на аренду квартиры и сделала для этого довольно сложную предварительную обработку данных, в результате чего мне удалось отправлять только один запрос в секунду. Чтобы собрать объявления размером в 4K, моя программа должна проработать около часа.
Чтобы отправлять запросы параллельно, вы можете воспользоваться пакетом multiprocessing.
Допустим, у нас есть 100 страниц, и мы хотим назначить каждому процессу равное количество страниц для обработки. Если n — количество процессоров, то вы можете равномерно распределить все страницы на n частей и назначить каждую часть отдельному процессору. Каждый процесс будет иметь свое имя, свою целевую функцию и свои аргументы для работы. После этого имя процесса можно использовать для включения записи данных в определенный файл.
Я назначила 1K страниц для каждого из 4-х процессоров, имевшихся у меня в распоряжении, в результате было создано 4 повторных запроса в секунду, что сократило время сбора данных моей программой до 17 минут.
[python]
import numpy as np
import multiprocessing as multi
def chunks(n, page_list):
"""Splits the list into n chunks"""
return np.array_split(page_list,n)
cpus = multi.cpu_count()
workers = []
page_list = [‘www.website.com/page1.html’, ‘www.website.com/page2.html’
‘www.website.com/page3.html’, ‘www.website.com/page4.html’]
page_bins = chunks(cpus, page_list)
for cpu in range(cpus):
sys.stdout.write("CPU " + str(cpu) + "\n")
# Process that will send corresponding list of pages
# to the function perform_extraction
worker = multi.Process(name=str(cpu),
target=perform_extraction,
args=(page_bins[cpu],))
worker.start()
workers.append(worker)
for worker in workers:
worker.join()
def perform_extraction(page_ranges):
"""Extracts data, does preprocessing, writes the data"""
# do requests and BeautifulSoup
# preprocess the data
file_name = multi.current_process().name+’.txt’
# write into current process file[/python]
Удачного скрэпинга!

[customscript]techrocks_custom_after_post_html[/customscript]
[customscript]techrocks_custom_script[/customscript]
Привет, можешь мне помочь с этим? :).
Будет скучно — напиши в скайп Akilak11 или телеграмм @Throling
я не фанат питона), но надо как-то вникнуть))