Неочевидные приемы для глубокого обучения, сокращающие время выполнения моделей и повышающие точность их результатов опубликовал сайт proglib.io со ссылкой на Towards Data Science. Код прилагается.

Модели глубокого обучения, например, сверточные нейронные сети, имеют множество гиперпараметров. При поиске их оптимальных величин по однородной сетке требуются аппаратные и временные ресурсы. Рассмотрим семь способов, как сократить время обучения моделей и повысить их точность.
1. Используйте для глубокого обучения мощные архитектуры
Узнайте о преимуществах технологии переноса обучения (transfer learning) и изучите архитектуры сверточных нейросетей. Используйте профессионально сделанный на промышленных мощностях велосипед или хотя бы в деталях освойте его устройство прежде, чем изобретать свой. Соответствующие примеры предобученных моделей найдутся для всех популярных фреймворков: Keras (Список Kaggle, Приложение Keras, Пример OpenCV), TensorFlow (VGG16, ResNet), Torch (LoadCaffe), Caffe (Model Zoo).
2. Используйте малые скорости обучения для предобученных моделей
Заранее настроенные веса – это не то же самое, что инициализированные случайным образом. Изменяйте их значения более деликатно. Выбор скорости зависит от модели обучения и того, насколько хорошо прошло предобучение.
3. Играйте с прореживанием (dropout)
Как и в случае регуляризации регрессионных моделей Ridge и LASSO, в глубоком обучении нет оптимальных для всех моделей значений альфа и прореживания. Эти гиперпараметры необходимо настраивать. Начиная с больших вариаций, при помощи np.logspace() уменьшайте интервал рассмотрения параметра аналогично скорости обучения. Общие стратегии следующие:
- Используйте небольшие проценты прореживания: 20-50% для скрытых слоев и 20% для входных значений. Слабые дропауты не приводят к существенным эффектам, а слишком сильное прореживание вызывает недообучение.
- Применяйте прореживание не только на скрытых слоях, но и на входном слое. Это также повышает эффективность обучения.
- Тренируйте большие нейросети. Вы получите лучшую производительность, когда прореживание происходит в крупной сети, это дает модели больше возможностей для изучения независимых представлений.
4. Ограничивайте размеры весов
Чтобы обобщить модель, ограничьте абсолютные значения весов для определенных слоев. Покажем на примере датасета MNIST, как в Keras можно варьировать и прореживание, и величины весов:
[python]# dropout во входном и скрытом слоях
# ограничиваем веса в скрытых слоях
# максимальная норма веса не превышает пяти
model = Sequential()
model.add(Dropout(0.2, input_shape=(784,))) # dropout on the inputs
# это помогает имитировать шум или отсутствующие данные
model.add(Dense(128, input_dim=784, kernel_initializer=’normal’, activation=’relu’, kernel_constraint=maxnorm(5)))
model.add(Dropout(0.5))
model.add(Dense(128, kernel_initializer=’normal’, activation=’tanh’, kernel_constraint=maxnorm(5)))
model.add(Dropout(0.5))
model.add(Dense(1, kernel_initializer=’normal’, activation=’sigmoid’))
[/python]
Так замораживаются веса в первых пяти слоях:
[python]for layer in model.layers[:5]:
layer.trainable = False
[/python]
Как вариант, можно установить для определенных слоев нулевую скорость обучения. Либо использовать алгоритм адаптивного обучения каждого параметра, например, Adadelta или Adam. Это несколько сложнее и лучше оформлено в Caffe.
5. Не трогайте первые слои
Первые скрытые слои нейронной сети обычно захватывают универсальные интерпретируемые признаки, такие как формы, кривые и пересечения. Просто оставьте их в покое.
6. Модифицируйте выходной слой
Замените стандартные значения по умолчанию новой функцией активации с размером вывода, подходящим для выбранной области. Не ограничивайтесь очевидным решением. Так, для MNIST кажутся достаточными 10 классов выходных данных. Однако использование 12-16 классов позволяет улучшить и разрешение вариантов, и качество модели. Пример модификации выходного слоя в Keras c 14 классами для датасета MNIST:
[python]from keras.layers.core import Activation, Dense
model.layers.pop() # defaults to last
model.outputs = [model.layers[-1].output]
model.layers[-1].outbound_nodes = []
model.add(Dense(14, activation=’softmax’))[/python]
7. Визуализируйте данные моделей
Важно получать зрительное представление модельных данных. Уровень абстракции Keras позволяет о многом не думать, но не дает рассмотреть части модели для глубокого анализа. Приведенный ниже код позволяет визуализировать модели TensorFlow:
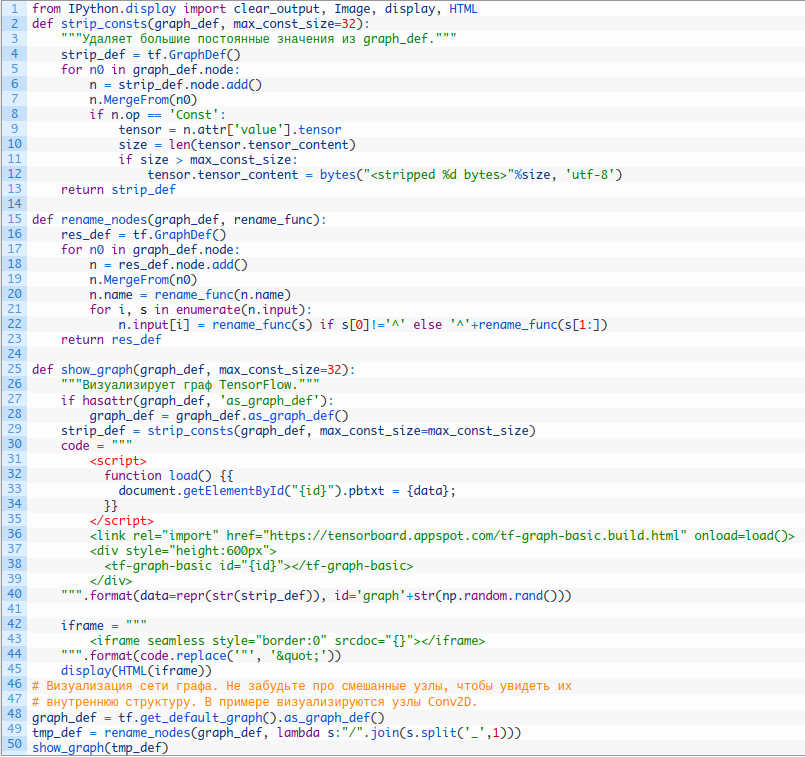
Следующая пара строк позволяет создать граф модели в Keras и сохраняет его в png-файле:
[python]from keras.utils import plot_model
plot_model(model, to_file=’model.png’)[/python]
Функция plot_model принимает также два опциональных булевых аргумента:
- show_shapes (по умолчанию False) определяет, будут ли выходные формы присутствовать на графе.
- show_layer_names (по умолчанию True) будут ли показываться на графе номера слоев.
Вы можете обработать объект pydot.Graph самостоятельно, например, в Jupyter-ноутбуке:
[python]from IPython.display import SVG
from keras.utils.visualize_util import model_to_dot
SVG(model_to_dot(model).create(prog=’dot’, format=’svg’))[/python]
Надеемся, что эта подборка рекомендаций для глубокого обучения поможет вам в ваших проектах.

[customscript]techrocks_custom_after_post_html[/customscript]
[customscript]techrocks_custom_script[/customscript]